
AIを下支えする基本概念を知っていますか?
現代では、音声・画像解析から自然言語の処理まで、AI が幅広い場面で活用されつつあります。こうした技術を理解するうえで重要なのが、数値やデータをコンピュータ上で扱う基礎理論です。情報量の単位やデジタル化の考え方を押さえることは、これからのキャリアにおいても大切な素養といえるでしょう。
たとえば、ルールベースから始まり、特徴量を抽出して学習する機械学習(教師あり・教師なし・強化学習)や、ニューラルネットワークの構造・バックプロパゲーション・活性化関数・過学習といった仕組みは、より高度なディープラーニングへ発展します。
さらに、事前学習やファインチューニング、転移学習といったアプローチに加え、画像解析に強みを持つ畳み込みニューラルネットワーク(CNN)、時系列データを扱うリカレントニューラルネットワーク(RNN)、生成モデルの一種である敵対的生成ネットワーク(GAN)などが登場し、近年は大規模言語モデル(LLM)やプロンプトエンジニアリングにも注目が集まっています。
これらの仕組みに目を向けることで、IT業界をはじめ様々な場面で期待される人材として活躍しやすくなるはずです。就職や転職など、未来の選択肢を広げるうえでも役立つ視点となるでしょう。
学習ポイントをチェック
- 情報量の単位を理解する背景
ビットやバイトなどの概念を押さえることで、データの保存や通信の仕組みを把握しやすくなる - AI 技術の多様な手法が注目される理由
機械学習やディープラーニングなど、問題ごとに適した方法を選択することで精度や効率が高まる - 大規模言語モデルが求められる場面
自然言語処理の高度化により、文章生成や応答の品質を大幅に向上できる

情報を扱う理論とAI 技術の基本を押さえておくと、幅広い応用の道が開けるでしょう。用語解説に目を通したら、練習問題にもチャレンジして理解を深めてみてください。
このページは以下の「ITパスポート シラバス6.3」学習用コンテンツです。
◆大分類:7.基礎理論
◆中分類:13.基礎理論
| ◆小分類 | ◆見出し | ◆学習すべき用語 |
|---|---|---|
| 35.情報に関する理論 | (5) AI(Artificial Intelligence:人工知能)の技術 | 自然言語処理(NLP) — ルールベース 特徴量 機械学習(教師あり学習,教師なし学習,強化学習) ニューラルネットワーク バックプロパゲーション 活性化関数 過学習 ディープラーニング 事前学習 ファインチューニング 転移学習 畳み込みニューラルネットワーク(CNN) リカレントニューラルネットワーク(RNN) 敵対的生成ネットワーク(GAN) 大規模言語モデル(LLM) プロンプトエンジニアリング |
AI(Artificial Intelligence:人工知能)の技術は多様な技術、データ、コンピューターリソース(計算能力)の集合体のようなものです。
以下の生成AI技術相関イメージ(ver1.0)で全体像を掴みながら学習しましょう。
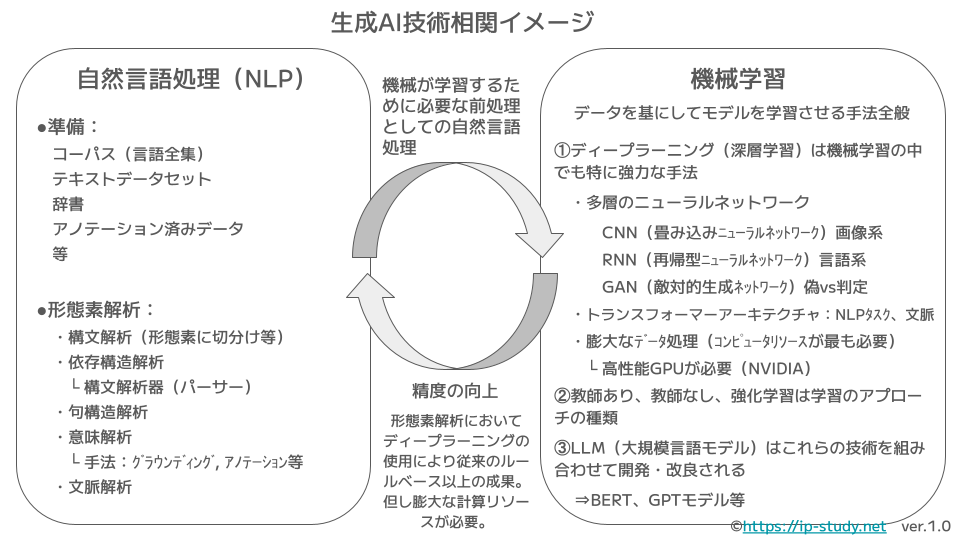

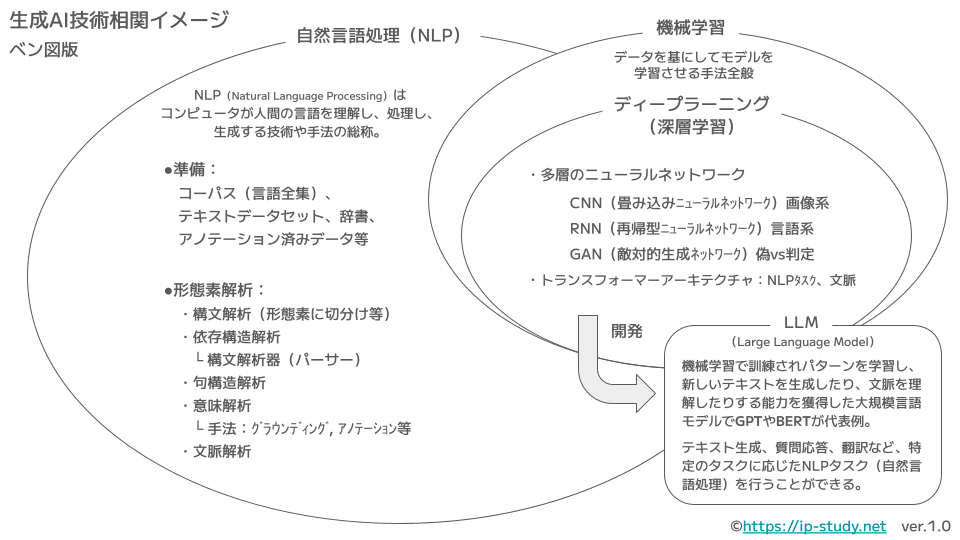
以下は「ベン図版」です。両方を見比べたりしながら全体像を掴んでおきましょう。
自然言語処理、機械学習、深層学習、LLM、大規模言語モデルなどの関係性は割と曖昧に使われていることも多いのでしっかり関係性を把握しておきたいとことです。
自然言語処理(NLP)
自然言語処理(Natural Language Processing、NLP)は、人間の言語をコンピュータが理解、解析、生成するための技術です。この技術はAI(人工知能)の一分野であり、音声認識、機械翻訳、感情分析、チャットボットなど、さまざまな応用分野があります。
NLPはテキストデータの構造化、意味理解、文脈処理などの課題に取り組むために統計的手法や機械学習モデル、特にディープラーニングが活用されます。
自然言語処理に関する学習用問題
自然言語処理の主な応用分野として適切でないものはどれですか?
自然言語処理に関連する技術として正しいものはどれですか?
自然言語処理における形態素解析の目的として適切なものはどれですか?
ルールベース
ルールベースとはあらかじめ定義されたルールに基づいてシステムが動作する方式です。
ルールは条件とその条件が満たされたときに実行される処理を定めたものであり、主にエキスパートシステムや単純な自動化タスクに利用されます。
ルールベースシステムは透明性が高く、ルールが明確に定義されているため、結果が予測しやすいのが特徴です。しかし、複雑な問題や変化する環境に対応するのが難しく、メンテナンスコストが高くなることがあります。
ルールベースに関する学習用問題
ルールベースの特徴として正しいものはどれですか?
ルールベースシステムが適している場面として最もふさわしいものはどれですか?
ルールベースシステムの課題として適切でないものはどれですか?
特徴量
特徴量とは機械学習モデルがデータから学習する際に利用するデータの属性や指標のことです。データセットから重要な情報を抽出し、機械学習モデルが予測や分類を行うための入力とします。
特徴量の選択とエンジニアリングがモデルの精度に大きく影響するため、特徴量の質を高めることが機械学習において重要です。代表的な特徴量には数値データやカテゴリデータ、テキストデータから生成されるものがあります。
特徴量に関する学習用問題
機械学習モデルの精度に最も影響を与える要因として適切なものはどれですか?
特徴量エンジニアリングとは何を指すか正しいものはどれですか?
特徴量として使用されるものとして適切でないものはどれですか?
機械学習(教師あり学習、教師なし学習、強化学習)
機械学習はデータからパターンや規則性を見つけ出し、その知見をもとに予測や分類を行う技術です。機械学習には教師あり学習、教師なし学習、強化学習の三つの主要なタイプがあります。
教師あり学習はラベル付きデータを用いて学習し、教師なし学習はラベルのないデータから構造を見つけます。強化学習は行動と報酬を通じて最適な行動方針を学習します。これらの手法は、タスクやデータの種類に応じて使い分けられます。
機械学習に関する学習用問題
教師あり学習の特徴として適切なものはどれですか?
強化学習の特徴として正しいものはどれですか?
教師なし学習に関する説明として最も適切なものはどれですか?
ニューラルネットワーク
ニューラルネットワークは生物の脳神経回路を模倣して作られた計算モデルです。
多数のノード(ニューロン)とそれらを結ぶエッジ(シナプス)から構成され、入力から出力へと情報を伝達しながら処理を行います。
ニューラルネットワークは多層にわたるネットワーク構造を持ち、特にディープラーニングにおいては非常に複雑なパターン認識を可能にします。この技術は画像認識、音声認識、自然言語処理など多くのAIアプリケーションに応用されています。
ニューラルネットワークに関する学習用問題
ニューラルネットワークにおけるノードの役割として正しいものはどれですか?
ニューラルネットワークの構造として適切でないものはどれですか?
ニューラルネットワークの主要な用途として適切でないものはどれですか?
バックプロパゲーション
バックプロパゲーション(Back propagation:誤差逆伝播)はニューラルネットワークの学習過程において誤差を逆伝播させ、各ノードの重みを調整するアルゴリズムです。
入力データがネットワークを通過する際に出力された結果と正解との差を誤差として計算し、その誤差が最小になるように重みを更新していくことでネットワーク全体の性能が向上し、より正確な予測や分類が可能になります。バックプロパゲーションはディープラーニングの成功に不可欠な技術です。
バックプロパゲーションに関する学習用問題
バックプロパゲーションの主な目的として正しいものはどれですか?
バックプロパゲーションの過程で計算されるものとして適切なものはどれですか?
バックプロパゲーションにおける誤差逆伝播の流れとして適切でないものはどれですか?
活性化関数
活性化関数はニューラルネットワークにおいて各ノードが次の層に出力する値を決定するために用いられる関数です。
活性化関数を用いることで、線形ではない複雑な関係性をモデルに学習させることが可能になります。
代表的な活性化関数には、シグモイド関数、ReLU(Rectified Linear Unit)、およびソフトマックス関数などがあります。適切な活性化関数を選択することが、ニューラルネットワークの性能に大きな影響を与えます。
活性化関数に関する学習用問題
活性化関数の役割として最も適切なものはどれですか?
活性化関数として一般的に使用されないものはどれですか?
ReLU(Rectified Linear Unit)に関する説明として正しいものはどれですか?
過学習
過学習とは機械学習モデルが訓練データに対して過度に適合し、汎用性が低下してしまう現象を指します。
過学習が起きると訓練データに対しては高い精度を発揮しますが、未知のデータに対しては性能が著しく低下します。
過学習を防ぐためには適切なデータの量や正則化、クロスバリデーションの実施が重要です。また、モデルの複雑さを抑えることも有効です。
過学習に関する学習用問題
過学習の症状として適切なものはどれですか?
過学習を防ぐための方法として最も適切なものはどれですか?
過学習が発生した場合、最も考えられる原因はどれですか?
ディープラーニング
ディープラーニングはニューラルネットワークを用いた機械学習の一分野であり、多層のニューラルネットワークを通じて複雑なパターンを学習します。
大量のデータと高性能なコンピューティング資源を活用することで、画像認識、音声認識、自然言語処理などの分野で顕著な成果を上げています。
ディープラーニングは、特にビッグデータを扱う際にその性能を発揮し、人工知能の発展に大きく寄与しています。
ディープラーニングに関する学習用問題
ディープラーニングの特徴として最も適切なものはどれですか?
ディープラーニングが適用される分野として適切でないものはどれですか?
ディープラーニングが成功を収めている理由として適切でないものはどれですか?
事前学習
事前学習とは機械学習モデルを特定のタスクに対して学習させる前に、別のタスクであらかじめ学習しておくプロセスを指します。モデルが基本的な特徴をすでに学習しているため、ターゲットタスクでの学習が効率化されます。
特にディープラーニングにおいて大規模データセットを活用する際に効果的であり、ファインチューニングと組み合わせることで高いパフォーマンスを引き出すことができます。
事前学習に関する学習用問題
事前学習の利点として適切なものはどれですか?
事前学習が特に有効でないシチュエーションとして適切なものはどれですか?
事前学習と深い関連のある技術として正しいものはどれですか?
ファインチューニング
ファインチューニングとは事前学習済みのモデルを特定のタスクに合わせて再学習させるプロセスです。事前学習により基本的な特徴が学習されているため、ターゲットタスクでの学習は効率的に進行します。
ファインチューニングは少量のデータや特定の領域での高精度な予測が必要な場合に特に有効です。この手法により、事前学習モデルの強みを活かしつつ、特定のニーズに応じた最適なモデルを構築できます。
ファインチューニングに関する学習用問題
ファインチューニングの主な利点として最も適切なものはどれですか?
ファインチューニングが最も適している状況として適切なものはどれですか?
ファインチューニングが特に有効でない場合として最も適切なものはどれですか?
転移学習
転移学習とは既存のモデルや学習済みの知識を新しいタスクに再利用する機械学習の技術です。この手法により、少量のデータや限られた計算資源でも高いパフォーマンスを引き出すことができます。
転移学習は特に関連性のあるタスク間で効果を発揮し、画像認識や自然言語処理など多くの分野で広く利用されています。既存のモデルを新しい状況に適応させるための効率的な方法として、ディープラーニングと組み合わせて使われることが多いです。
転移学習に関する学習用問題
転移学習の利点として適切なものはどれですか?
転移学習が特に有効でない場合として適切なものはどれですか?
転移学習に関連する技術として適切なものはどれですか?
畳み込みニューラルネットワーク(CNN)
畳み込みニューラルネットワーク(CNN:Convolutional Neural Network)は、画像や動画の処理に特化したニューラルネットワークの一種です。
CNNは畳み込み層とプーリング層を組み合わせることで、画像の特徴を効果的に抽出し、分類や認識に利用します。特に、画像認識、物体検出、顔認識などの分野で広く使用されています。
CNNの構造はデータの空間的関係を保ちながら学習を行うため、従来の全結合層のみを用いたネットワークよりも高い精度を実現します。

画像の小さな部分(フィルタやカーネルと呼ばれます)を全体に「重ね合わせて」いく、数学的な「畳み込み(convolution)」という操作を行うことから「畳み込みニューラルネットワーク」という名称になっています。
畳み込みニューラルネットワーク(CNN)に関する学習用問題
畳み込みニューラルネットワーク(CNN)の特徴として適切なものはどれですか?
CNNにおける「畳み込み層」の役割として正しいものはどれですか?
畳み込みニューラルネットワーク(CNN)が特に効果的でない分野として適切なものはどれですか?
リカレントニューラルネットワーク(RNN)
リカレントニューラルネットワーク(RNN:Recurrent Neural Network)は時系列データやシーケンスデータを処理するために設計されたニューラルネットワークの一種です。
RNNは過去の情報を保持しつつ、現在の入力に影響を与えることができるため、音声認識、文章生成、翻訳などのタスクに適しています。
RNNの構造では各層が自分自身に再帰的に接続されており、これによりデータの時間的な依存関係を捉えることが可能になります。

「Recurrent」は何度も繰り返す、循環する、回帰性といった意味です。
リカレントニューラルネットワーク(RNN)に関する学習用問題
リカレントニューラルネットワーク(RNN)の特徴として適切なものはどれですか?
RNNが特に適しているタスクとして適切なものはどれですか?
RNNの構造として特徴的でないものはどれですか?
敵対的生成ネットワーク(GAN)
敵対的生成ネットワーク(GAN)は「生成モデル」と「識別モデル」という二つのニューラルネットワークを競わせることで、リアルなデータを生成する技術です。
生成モデルは偽のデータを生成し、識別モデルはそれが本物か偽物かを判別します。この競争の過程で、生成モデルはよりリアルなデータを作り出す能力を向上させます。GANは、画像生成、映像合成、データ補完など多様な分野で応用されており、その能力はAI分野で大きな注目を集めています。
敵対的生成ネットワーク(GAN)に関する学習用問題
敵対的生成ネットワーク(GAN)の主な構成要素として正しいものはどれですか?
GANの主な応用分野として適切でないものはどれですか?
敵対的生成ネットワーク(GAN)の識別モデルの役割として適切なものはどれですか?
大規模言語モデル(LLM)
大規模言語モデル(LLM)は非常に多くのパラメータを持ち、大量のテキストデータから学習して自然言語処理を行うモデルです。
これらのモデルは、文の生成、翻訳、質問応答など多様なタスクに高い精度で対応できることが特徴です。特に、BERTやGPTなどのモデルが代表例として知られ、テキストの意味理解や自然な文生成において優れた性能を示しています。LLMはその性能の高さゆえに、さまざまな分野での応用が進んでいます。
大規模言語モデル(LLM)に関する学習用問題
大規模言語モデル(LLM)の主な特徴として正しいものはどれですか?
LLMに該当しないモデルとして適切なものはどれですか?
LLMが主に用いられるタスクとして適切でないものはどれですか?
プロンプトエンジニアリング
プロンプトエンジニアリングとは大規模言語モデル(LLM)に対して適切な指示(プロンプト)を与えることで、期待する出力を得るための技術です。
プロンプトの設計次第でモデルの出力内容や品質が大きく変わるため、この技術はLLMの効果的な利用に不可欠です。プロンプトエンジニアリングはLLMの多様なタスクへの応用を可能にし、特定のタスクに対してより適切な応答を生成するために使用されます。
プロンプトエンジニアリングに関する学習用問題
プロンプトエンジニアリングの主な目的として正しいものはどれですか?
プロンプトエンジニアリングが特に有効でない場合として適切なものはどれですか?
プロンプトエンジニアリングが活用される分野として最も適切なものはどれですか?
生成AIを生み出す技術や背景といった要素は思ったより多岐に渡っており、一つ一つを単純に暗記するのではなく、全体構成をこのページ先頭の図解で掴んでおくことで理解がしやすく、また覚えやすくなる近道です。
